The Dropbox Traffic team is charged with innovating our application networking stack to improve the experience for every one of our users—over half a billion of them. This article describes our work with NS1 to optimize our intelligent DNS-based global load balancing for corner cases that we uncovered while improving our point of presence (PoP) selection automation for our edge network.By co-developing the platform capabilities with NS1 to handle these outliers, we deliver positive Dropbox experiences to more users, more consistently.
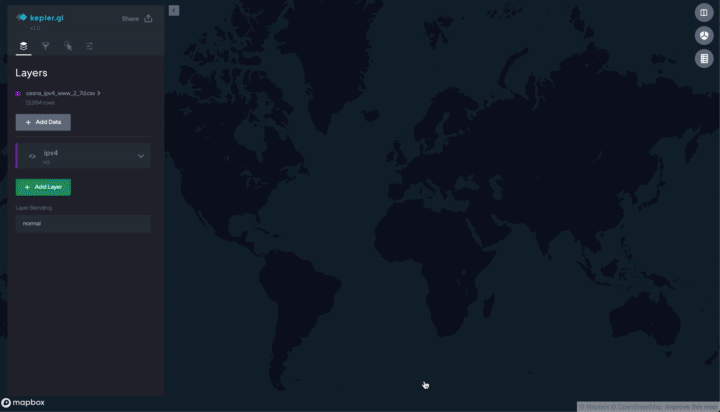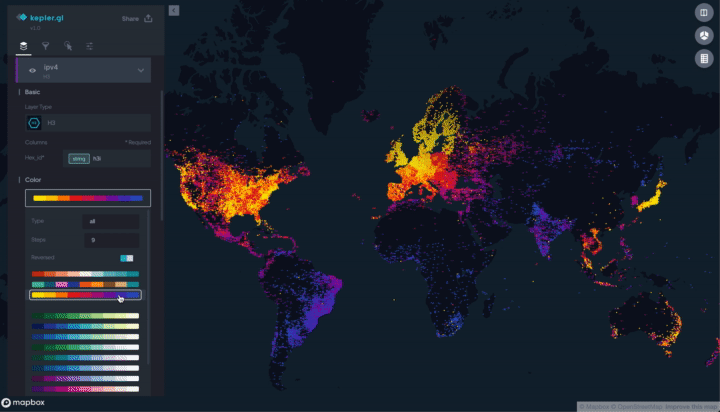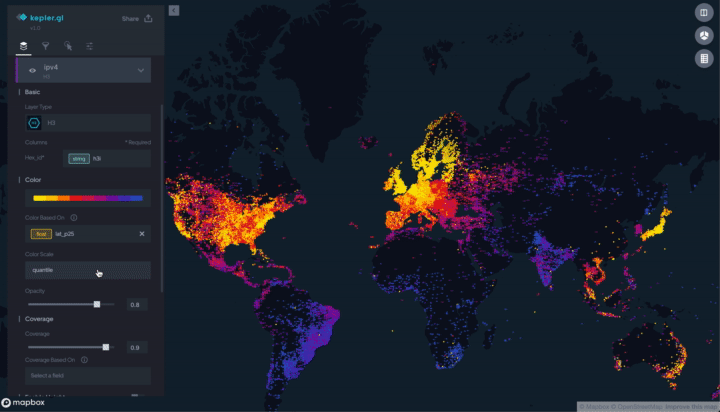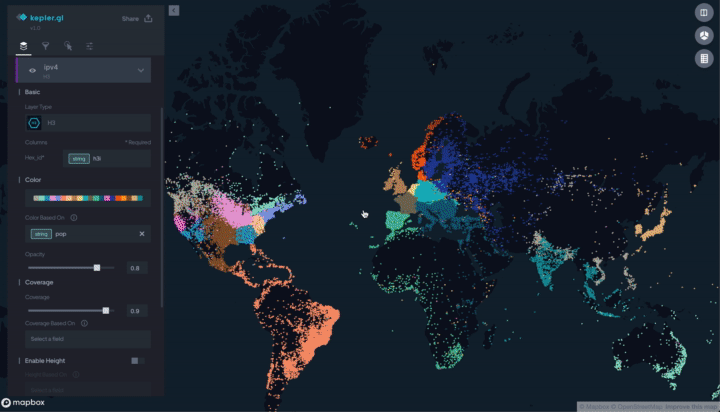
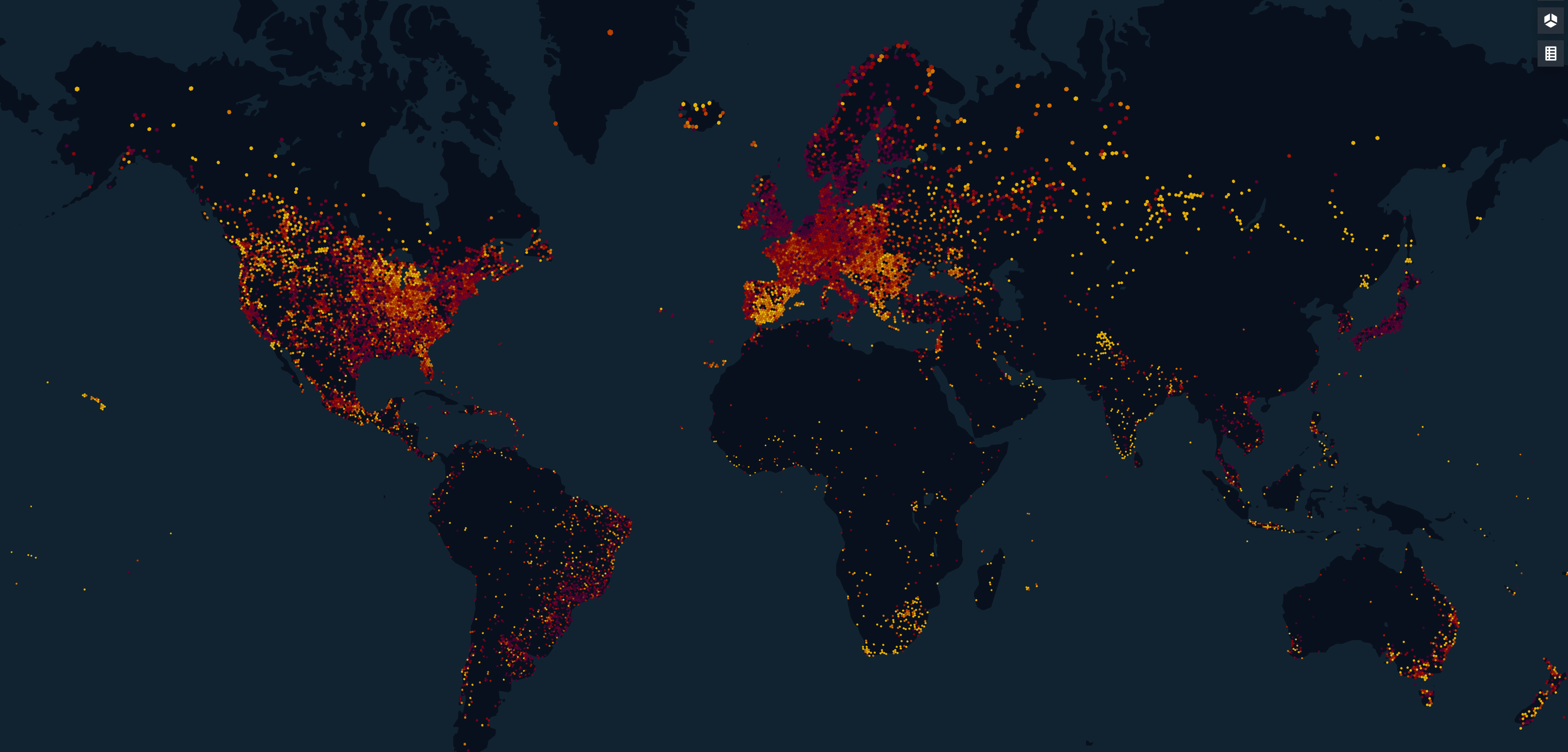
In our previous post about the Dropbox edge network, we were talking about geolocation-based load balancing. The idea behind this approach could be simply described as sending the user to our closest point of presence. Let’s try to decipher this statement: being sent in this context means that when a user is doing DNS request, we would reply with a specific Dropbox IP address. For different users, we reply with different IP addresses. With geolocation-based load balancing, the “closest” PoP is indeed the one which is closest in terms of distance from the user. In the picture below you can see how users are mapped to our edge PoPs.
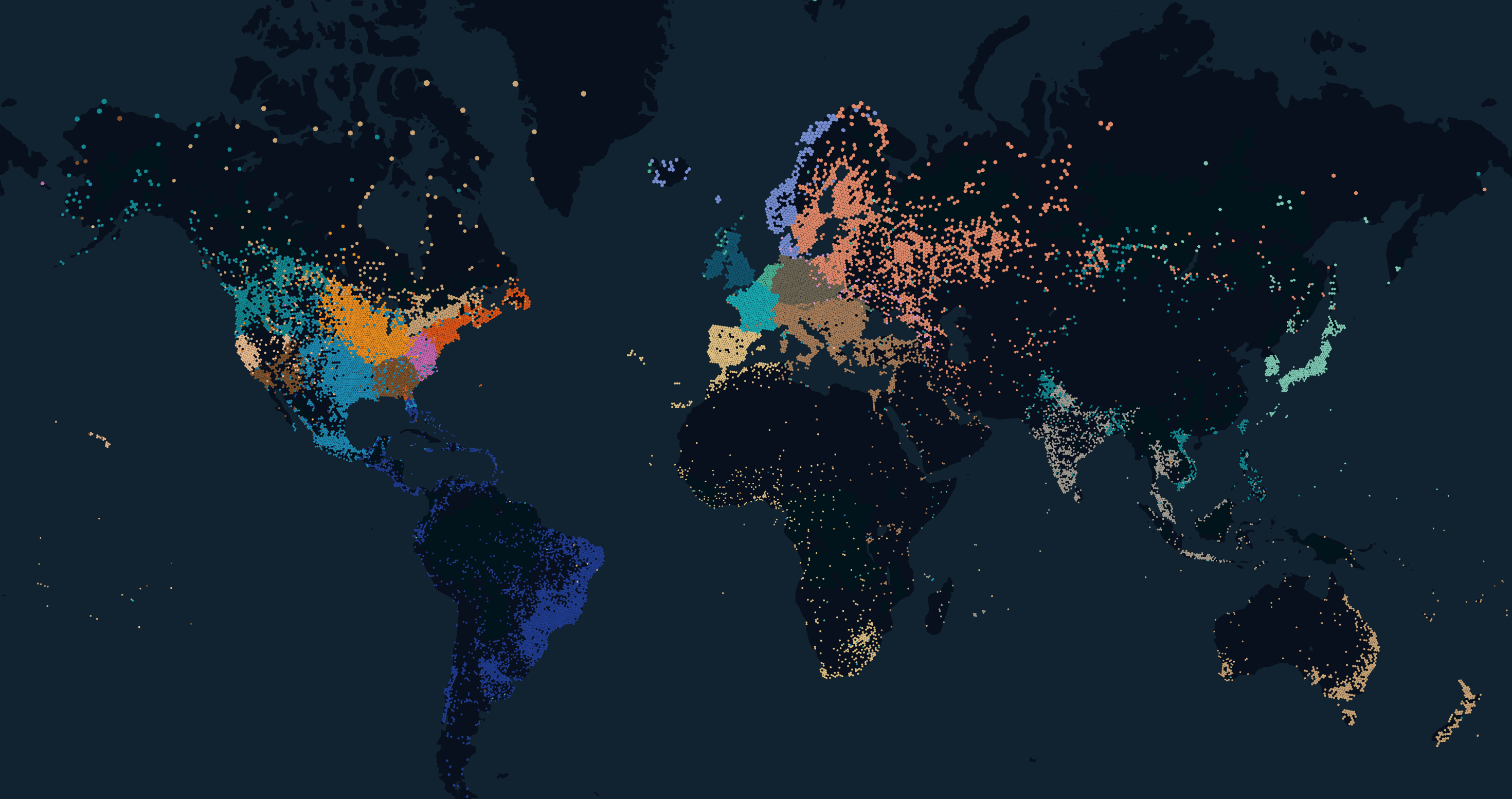
This map was generated by kepler.gl with the help of a database with IP to geolocation mappings. IP addresses were used to preserve the privacy of our users. Dropbox intentionally does not use any other information to determine user locations. This works for the majority of cases and has allowed us to scale our edge network to more than 20 edge clusters. However, there are some corner cases where geolocation does not work as intended (even on the map above you can see that sometimes a user is mapped to an unrealistic location). Let’s understand why.
When geolocation load balancing doesn’t work
The main drawback of geo routing is that it does not consider the network’s topology. For example, a user could be right next to our PoP but his ISP does not have any network interconnection with us in that location. The example below illustrates this situation.
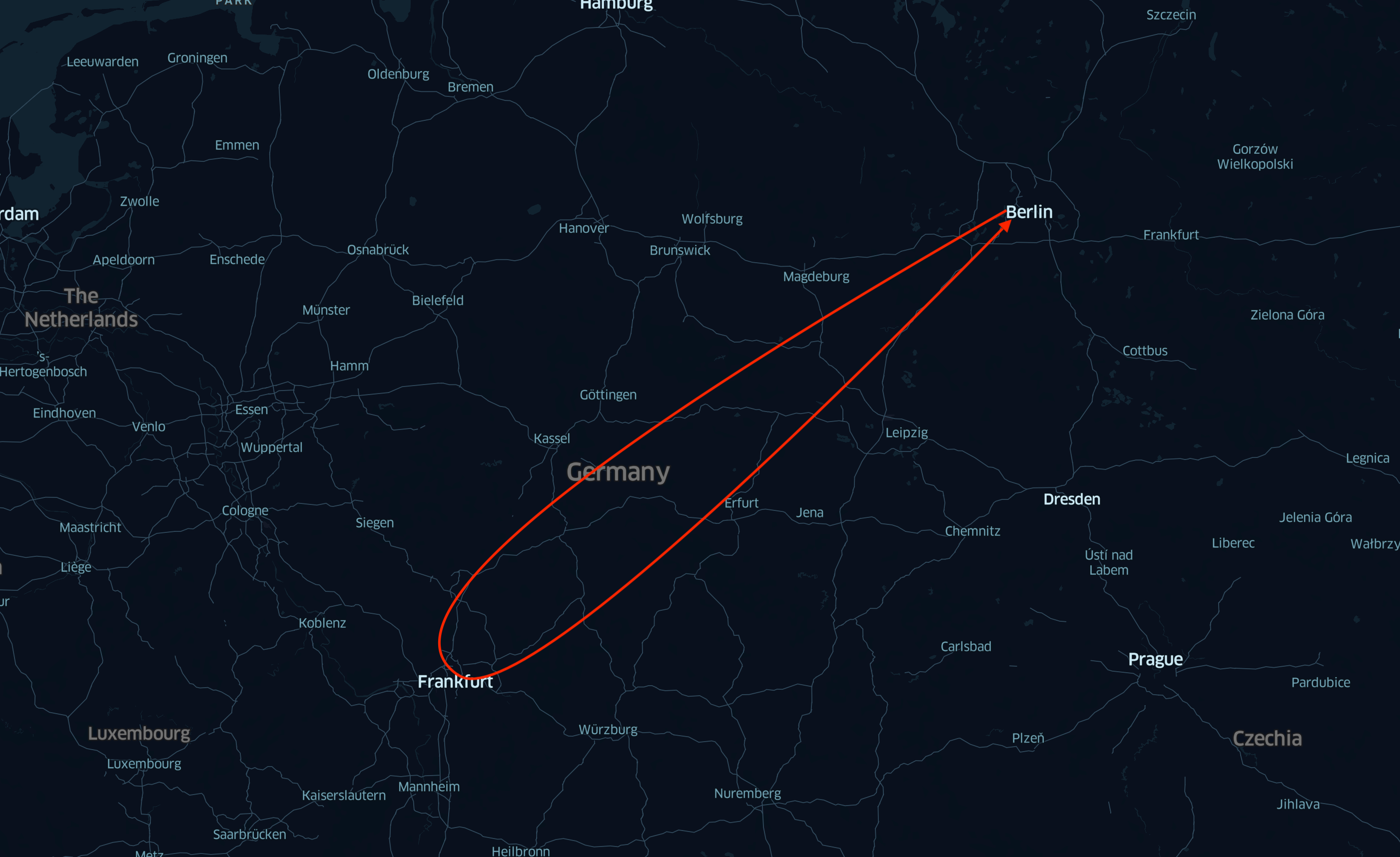
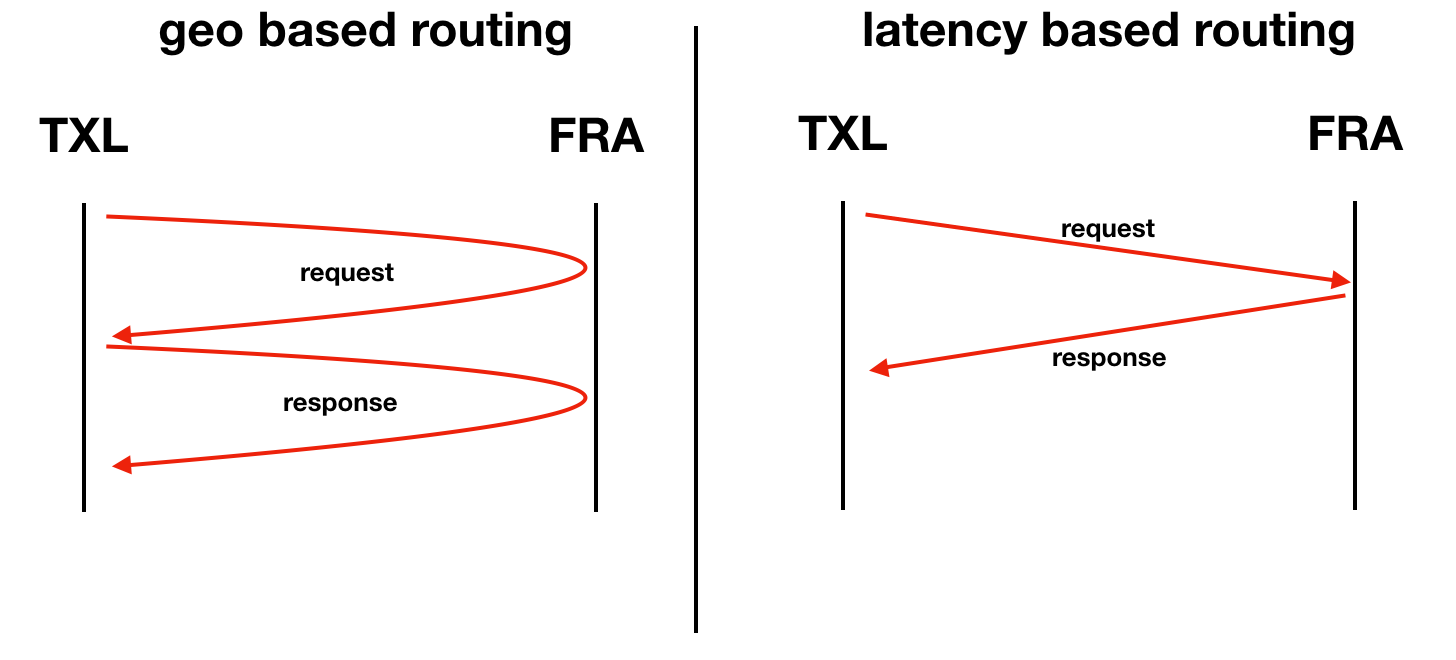
In this example, an ISP in Berlin ( TXL IATA code) has a user. From the IPS’s geographical point of view, the closest PoP is in Berlin, but we don’t have any PNIs (private network interconnections) with the ISP there. In this situation, the ISP would need to use a transit provider to reach us. In some cases, the connection with the transit provider could be in other facilities where we do have a PoP as well, for instance Frankfurt (FRA). But instead of going through Frankfurt (TXL→FRA→TXL), the client’s traffic is looping back to Berlin (TXL→FRA→TXL→FRA→TXL). One way to solve the issue is setting up a PNI with an ISP in TXL. Dropbox has an open peering policy and highly benefits from direct interconnects. Although we are trying to find all such cases, it is unrealistic to track them all, and we still have corner cases, when geo routing does not work.
Let’s look at some extreme examples of such suboptimal routing.
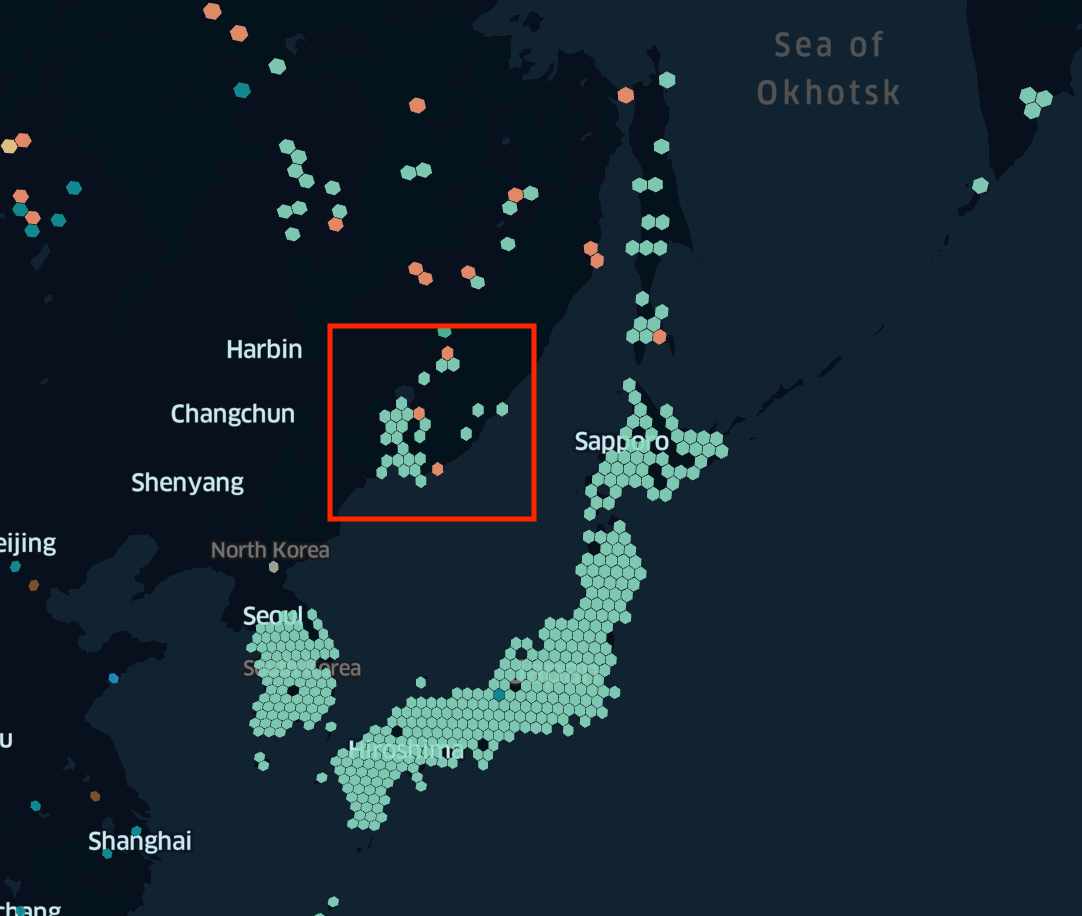
In this example users in Vladivostok, Russia (marked as a red square) are routed to our PoP in Tokyo (as you can see them from the geographical point of view they are right next to each other). The issue here is that most ISPs in Russia do not have any presence in Tokyo. Moreover, most of the transit connections happened in the west part of Russia. So in this example, 75th percentile of RTT between the user and a Dropbox frontend server is around 300-400 ms. For them to reach us their traffic must travel across the globe (e.g., Vladivostok→Moscow→Atlantic Ocean→USA→Pacific Ocean→Tokyo).
How to improve DNS load balancing
The best way to improve DNS load balancing and avoid such corner cases, is to “teach” it about your network topology. Instead of routing based on geographical “closeness,” we would use routing based on latency/network topology “closeness,” (the lower latency to the PoP → the closer it is). After obtaining such a route map (a user to PoP mapping) the next step is to teach your DNS server to use it. In our case, we collaborated with NS1 and added the ability to upload and use a custom DNS map on a per-record basis.
Building our map (initial version)
The question is, once we have a way to use a custom map to improve users’ routing, how could we build such a map? We already had the latency data between users’ subnet and our edge PoPs. (As we described in the previous article about our edge network, we have heavily invested in our desktop client framework so we can use it to run simple tests, e.g. measure latency between a client and every Dropbox edge cluster.) But for the DNS map we also need to get a mapping between a user’s subnet and the DNS resolver they are using. At this point, we want to briefly remind the reader about how DNS resolution works. The picture below shows the steps involved:
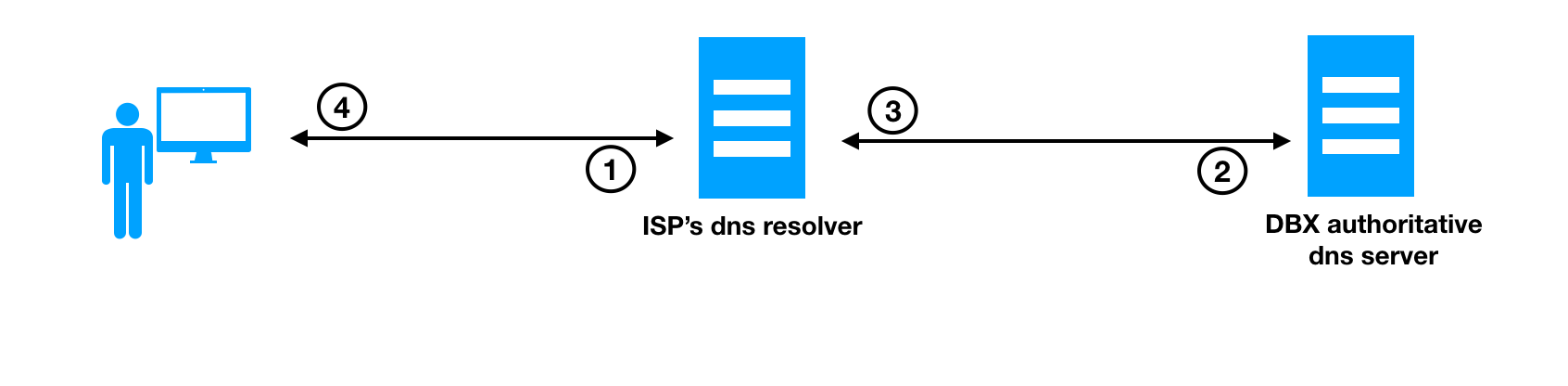
- The user opens www.dropbox.com in a browser or starts the Dropbox desktop client which attempt to resolve DNS record of www.dropbox.com to our IP address. This step involves sending a DNS query to the configured DNS resolver (usually the one, which the ISP provides)
- The DNS resolver iterates through requests to the authoritative DNS server for the dropbox.com zone (assuming it does not have cached reply for this entry; if it does, see step 4 below)
- The DNS server replies with the IP address of www.dropbox.com
- The ISP’s recursive DNS resolver replies to the end-user with an IP address for www.dropbox.com
As you can see from the described process, the authoritative DNS server does not see the end user’s IP address, but the IP address of the user’s DNS resolver. (Recently, some public DNS resolvers started to provide DNS ECS extensions, but they are still not widely used. See appendix C.) We faced a problem of needing to know which DNS resolver a user is using. Fortunately, others have solved this problem (e.g. Facebook’s sonar/doppler) and some solutions were already documented.
In our case, we added a special test to our client framework, that does DNS queries to random subdomains of dropbox.com. By being random, we make sure that the user’s DNS resolver doesn’t have any cached replies and we force it to do a full DNS lookup. On our side, we are logging all requests to this subdomain, and getting a mapping between unique DNS name ↔ DNS resolver’s IP address. At the same time, our desktop client periodically reports back to us which unique DNS queries it has been issuing (we anonymize this data in our system as much as possible. For example, we do aggregate all this data by a subnet, but we do not log a user’s individual IP address). By joining these two sources of data we are getting information about the client’s subnet ↔ DNS resolver ↔ latency to the PoP. And this is all that we need to build an initial map for latency-based DNS routing: we know all the user’s information behind certain DNS resolvers, and latency of this user toward all of our PoPs. By doing a few transformations, we learn what is the best PoP for most of the users behind this DNS resolver (in our case we are calculating 75th percentile).
The format of the map which NS1 expects is very simple: you just need to create a mapping between subnets (where DNS resolvers are located) and the PoP (which is identified by a configurable tag, in our case we are using IATA codes for tagging). The map itself should be serialized as a JSON message
{
"meta": {
"version": 1
},
"map": [
{
"networks": [
"172.16.0.1/24",
"172.16.0.2/24"
],
"labels": [
"fra"
]
},
{
"networks": [
"172.16.0.3/24",
"172.16.0.4/24"
],
"labels": [
"txl"
]
}
]
}
As you can see, there is no user specific data in this map, only IP addresses/subnets of resolvers and where to send them. NS1, if configured, allows us to use multiple maps, and also supports DNS ECS matching (e.g. if an incoming request has ECS info about a user’s subnet, it would try to look up this subnet, and only fallback to the resolver’s IP address if this lookup fails). As the last step in our pipeline, we upload a map into NS1 using their API.
Initial results
We have started to deploy this map for our test domain and compare it to a geo-based DNS map. Almost immediately we saw around 10-15% latency improvement for our users (both for 75th and 95th percentile, with no negative effects at higher percentiles).
Here is an example of how it improved our latency in Africa and US:


The next step was to get a PDF (probability density function) on exactly how much better a latency-based map is vs a geo-based one. We decided to compare the latency-based map vs anycast (we use anycast routing for apex record of dropbox.com).
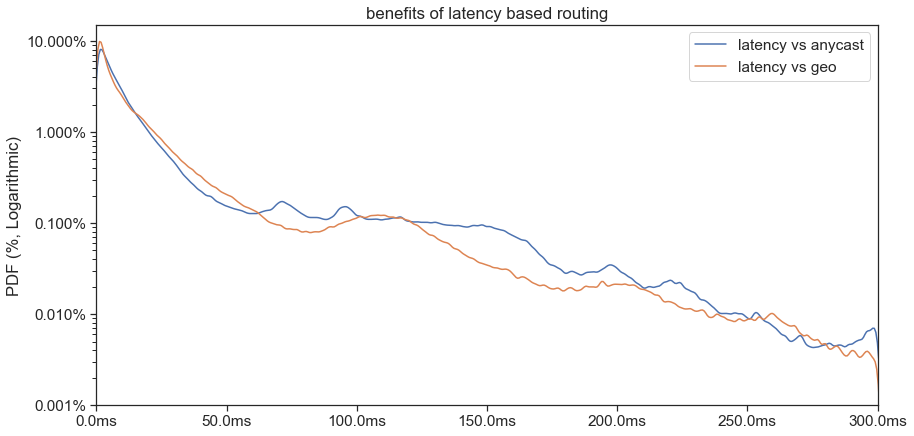
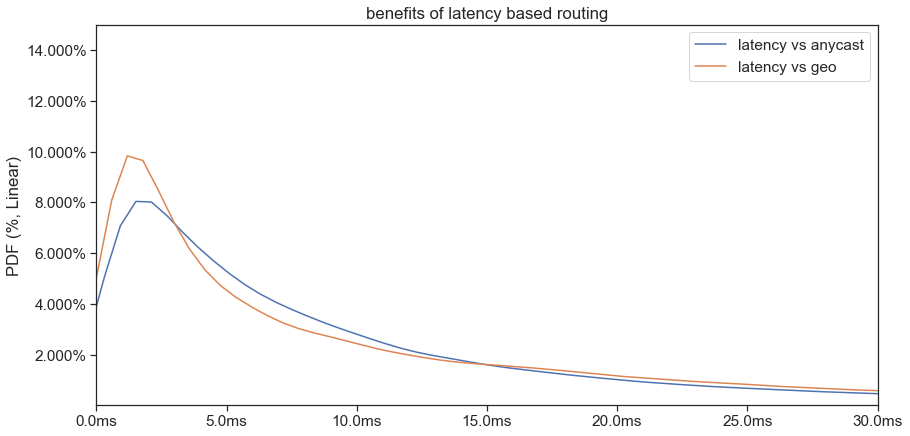
As you can see from the PDF graphs, around 10% of our user saw 2 ms improvements, 1% got around 20 ms improvements and “long tail” saw up to 200 ms and above.
Overall, it looked like we had some benefit from latency-based routing almost everywhere (on a map bellow the brighter the hexagons are, the larger benefit in terms of latency of connection). latency-based DNS routing allows us to utilize existing PoPs better by getting more performance from the same infrastructure.
Solving corner cases
But the biggest source of these improvements was the fact that we were able to eliminate corner cases of geo-based routing. Let's revisit the example with Vladivostok from above.
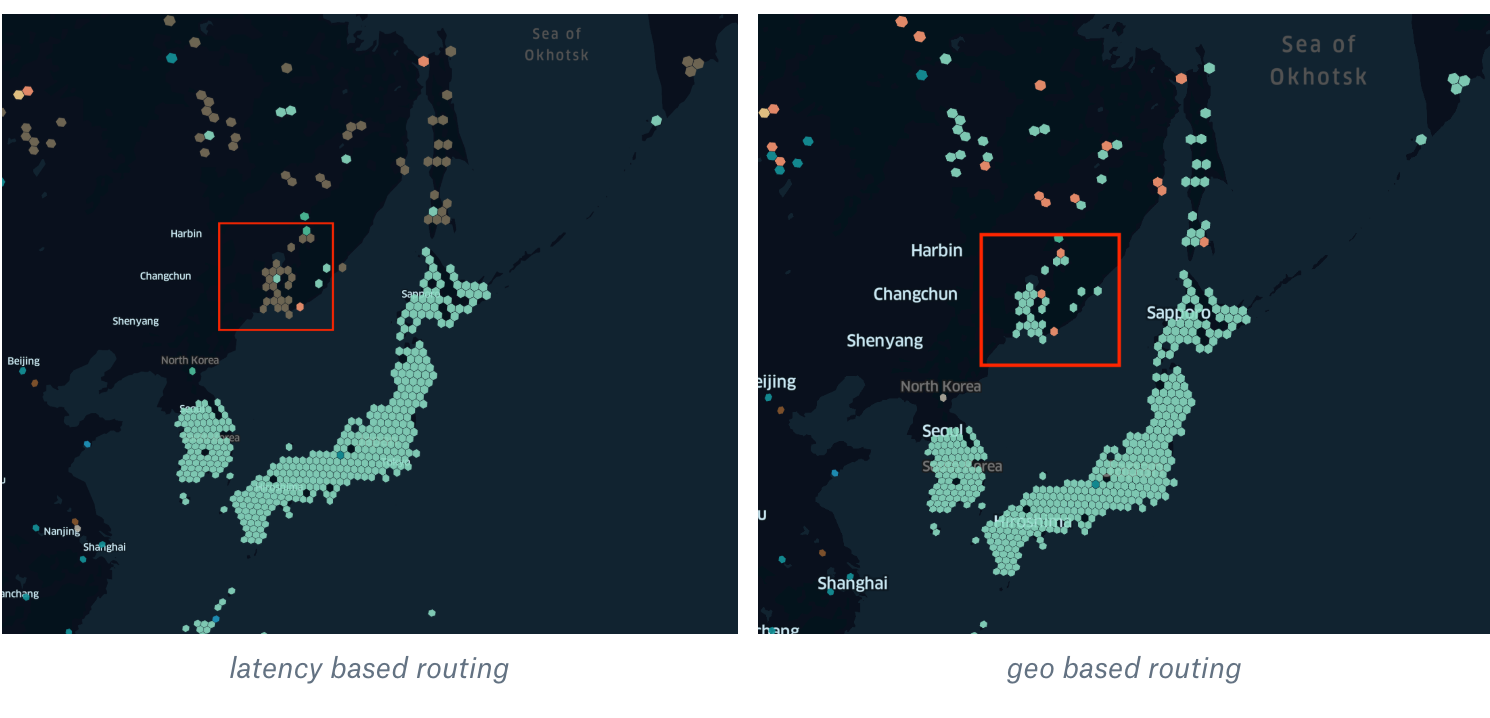
The different color means that we have started to route users to another PoP. In this example, instead of sending them across the world to Tokyo, we have started to route them to Frankfurt, which is one of the biggest internet exchange points in Europe. For Russian ISPs, this is one of the major locations to exchange traffic with other providers. For end-users, the latency went down from 300-400 ms to roughly 150.
Let’s look into some other examples:
Iceland
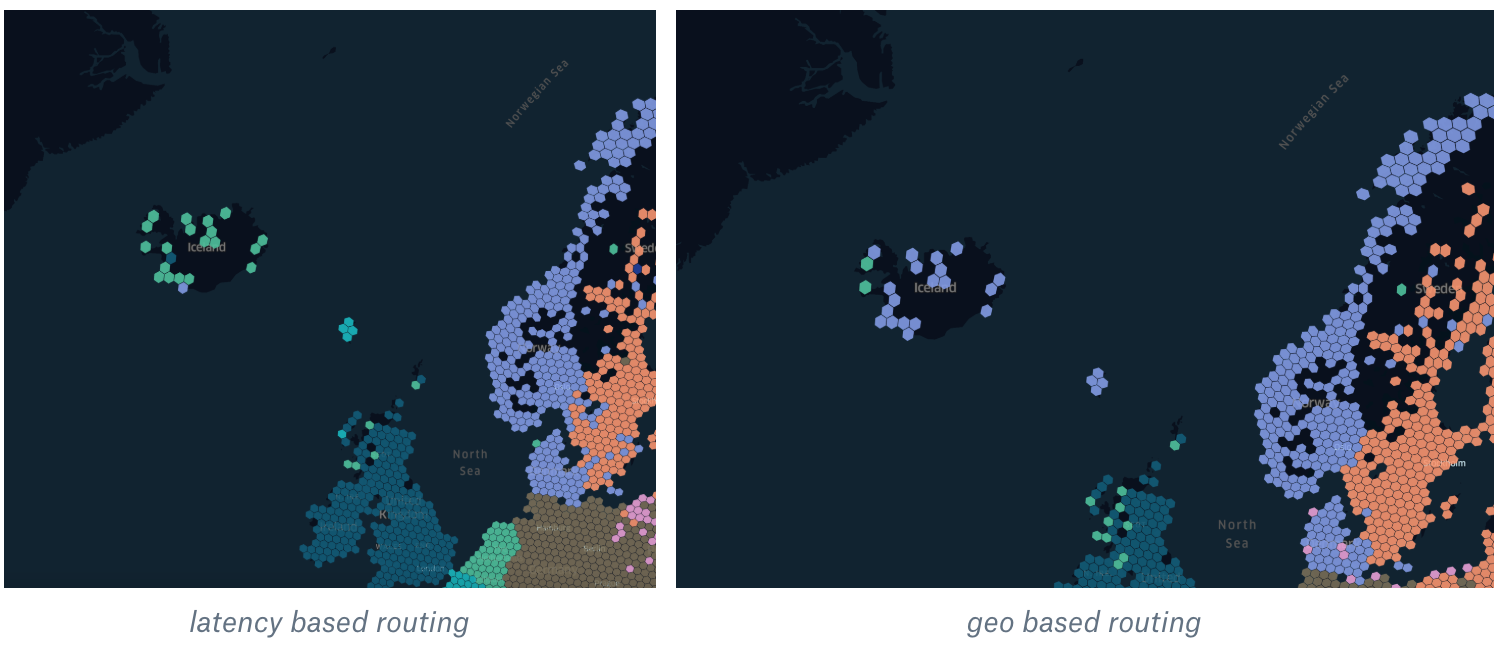
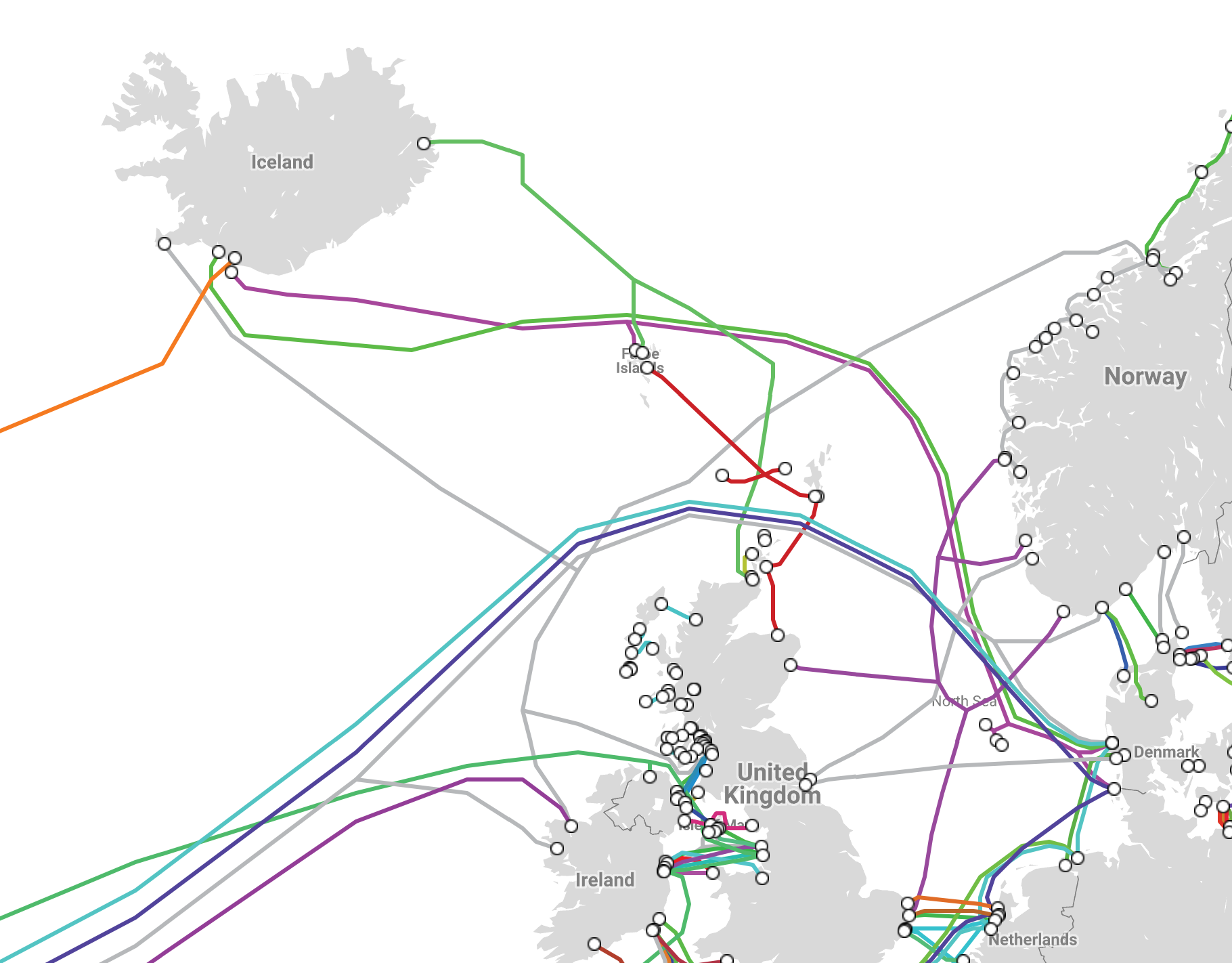
As you can see from the picture above, there is no direct cable from Iceland to Norway. Instead, most of the network cables go to Denmark, which is much closer to the Netherlands (and Amsterdam) than Oslo. Using latency-based routing decreased the latency for users in Iceland by 10-15%.
Another interesting example is Egypt:
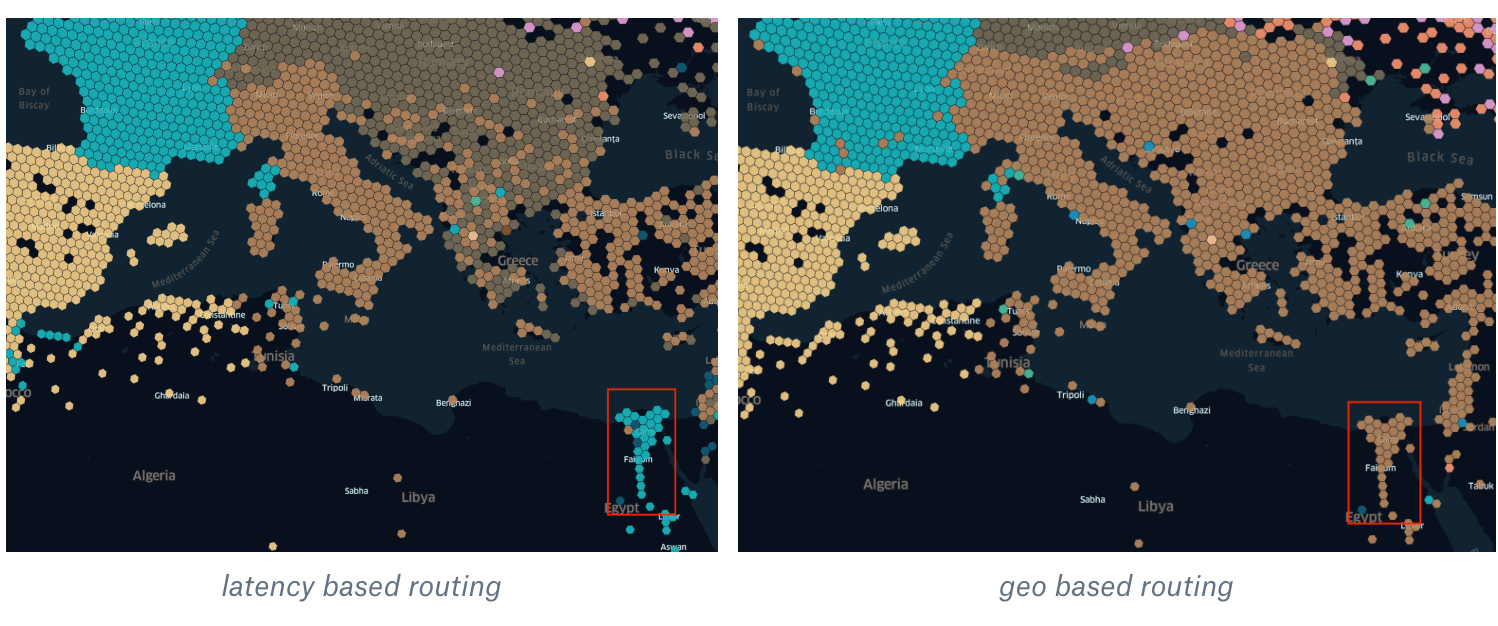
With geo routing, users in Egypt were being sent to our PoP in Milan, but with latency-based routing, they are now using Paris as the best location. To understand why, let’s again look at the submarine cables map:
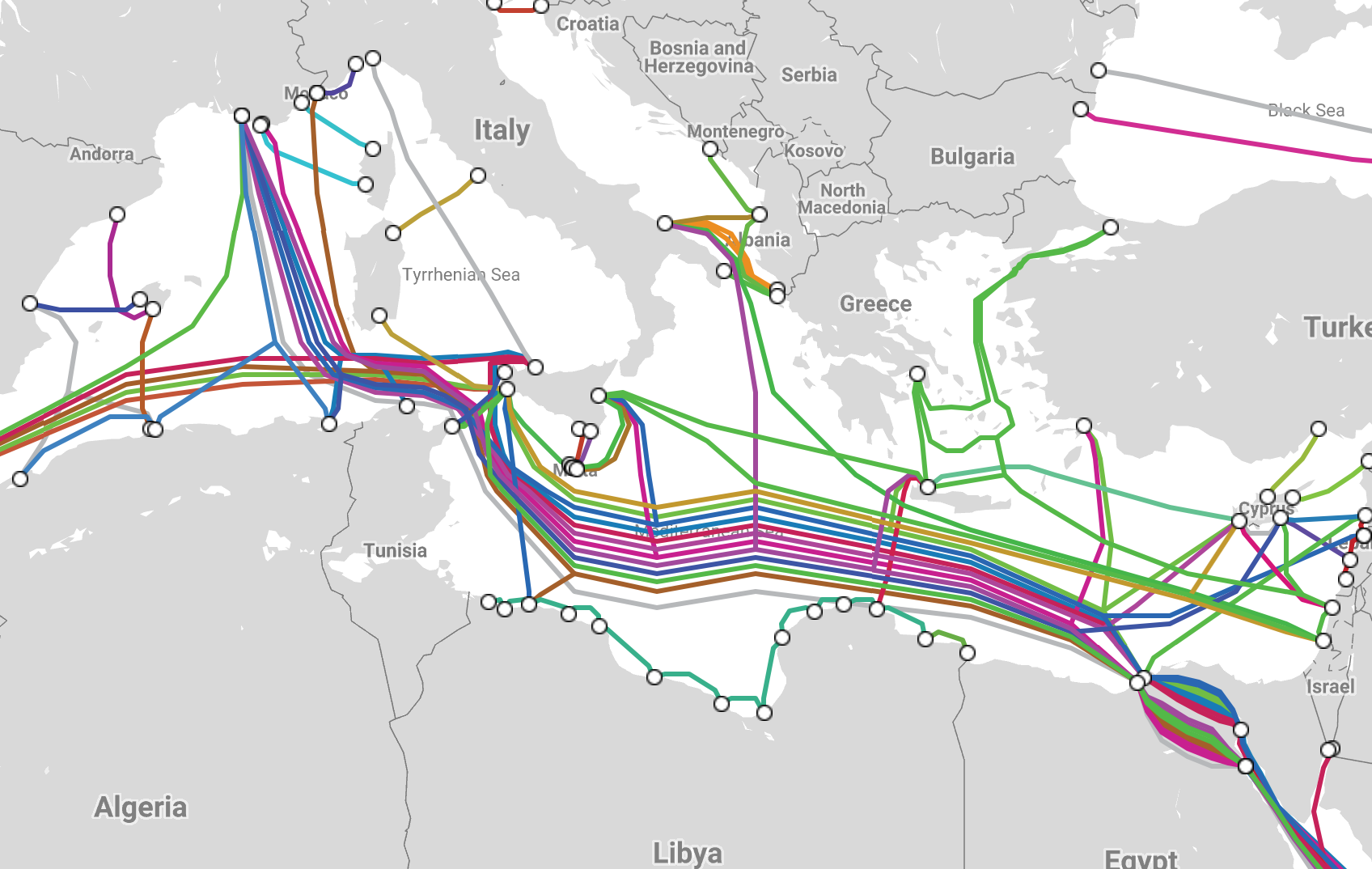
submarine cables map in Egypt As you can see, most of them are going from Egypt to France. Latency-based routing once again allowed us to get a 10% benefit in terms of latency.
If we look into Europe overall and compare geo vs latency-based routing we see another interesting fact: ISPs do prefer to peer with each other in a few big internet exchange points.
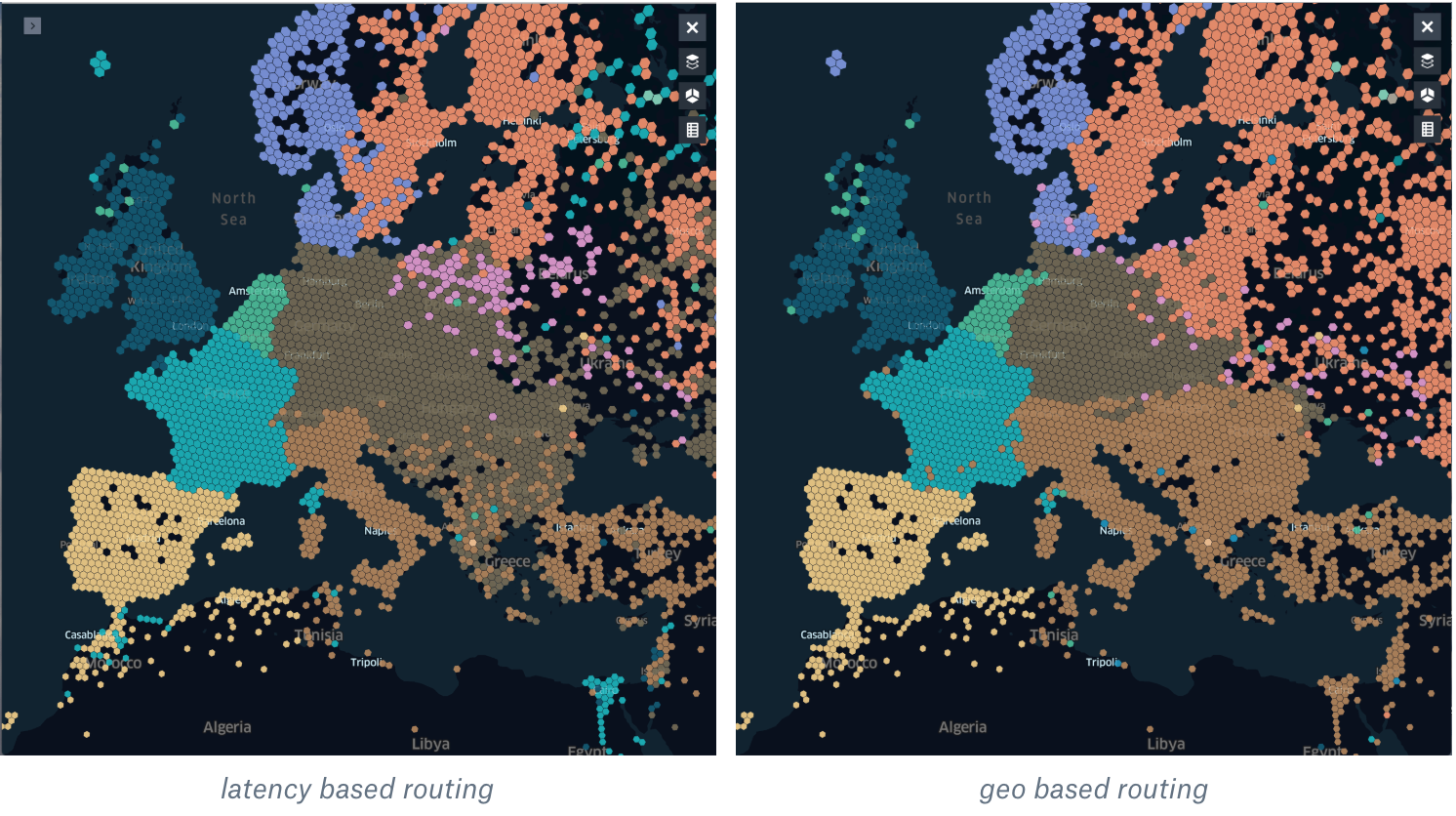
You can see pretty straight borders with geo-based routing, however latency-based shows a different picture. Most of the ISPs in central Europe prefer to use Frankfurt to exchange traffic between each other. Also, the latency-based map shows how this routing allows us to fully utilize our PoP in Berlin (purple hexagons): with geo-based routing, we saw performance degradation for our users there (most likely because their ISPs have not had PNIs with us in Berlin). Because of that, with geo-based routing, we were using this PoP only for whitelisted ISPs.
What comes next
We just started to deploy a latency-based map in production, and this is just an initial version. There are lots of ways to improve it and make it much more intelligent. For example, right now the initial version does not consider any BGP policy (e.g. for specific ISPs to prefer locations with direct peering) and this is our top priority to implement in the next iteration of this project. Another interesting approach is to dynamically allocate users to the PoPs based on load (today we are using static weights, however, we are planning to add a feedback loop based on the actual usage of the PoP).
We’re hiring!
If you are still here, there is a high chance that you actually enjoy digging deep into the performance data and you may enjoy working at the Dropbox Traffic team! Dropbox has a globally distributed Edge network, terabits of traffic, and millions of requests per second. All of which is managed by a small team in Mountain View, CA.
The Traffic team is hiring both SWEs and SREs to work on TCP/IP packet processors and loadbalancers, HTTP/gRPC proxies, and our internal gRPC-based service mesh. Not your thing? Dropbox is also hiring for a wide variety of engineering positions in San Francisco, New York, Seattle, Tel Aviv, and other offices around the world.
Appendix A. Dropbox Open Peering Policy
Appendix B. Visualization with Kepler.gl and h3