

Camera uploads is a feature in our Android and iOS apps that automatically backs up a user’s photos and videos from their mobile device to Dropbox. The feature was first introduced in 2012, and uploads millions of photos and videos for hundreds of thousands of users every day. People who use camera uploads are some of our most dedicated and engaged users. They care deeply about their photo libraries, and expect their backups to be quick and dependable every time. It’s important that we offer a service they can trust.
Until recently, camera uploads was built on a C++ library shared between the Android and iOS Dropbox apps. This library served us well for a long time, uploading billions of images over many years. However, it had numerous problems. The shared code had grown polluted with complex platform-specific hacks that made it difficult to understand and risky to change. This risk was compounded by a lack of tooling support, and a shortage of in-house C++ expertise. Plus, after more than five years in production, the C++ implementation was beginning to show its age. It was unaware of platform-specific restrictions on background processes, had bugs that could delay uploads for long periods of time, and made outage recovery difficult and time-consuming.
In 2019, we decided that rewriting the feature was the best way to offer a reliable, trustworthy user experience for years to come. This time, Android and iOS implementations would be separate and use platform-native languages (Kotlin and Swift respectively) and libraries (such as WorkManager and Room for Android). The implementations could then be optimized for each platform and evolve independently, without being constrained by design decisions from the other.
This post is about some of the design, validation, and release decisions we made while building the new camera uploads feature for Android, which we released to all users during the summer of 2021. The project shipped successfully, with no outages or major issues; error rates went down, and upload performance greatly improved. If you haven’t already enabled camera uploads, you should try it out for yourself.
Designing for background reliability
The main value proposition of camera uploads is that it works silently in the background. For users who don’t open the app for weeks or even months at a time, new photos should still upload promptly.
How does this work? When someone takes a new photo or modifies an existing photo, the OS notifies the Dropbox mobile app. A background worker we call the scanner carefully identifies all the photos (or videos) that haven’t yet been uploaded to Dropbox and queues them for upload. Then another background worker, the uploader, batch uploads all the photos in the queue.
Uploading is a two step process. First, like many Dropbox systems, we break the file into 4 MB blocks, compute the hash of each block, and upload each block to the server. Once all the file blocks are uploaded, we make a final commit request to the server with a list of all block hashes in the file. This creates a new file consisting of those blocks in the user’s Camera Uploads folder. Photos and videos uploaded to this folder can then be accessed from any linked device.
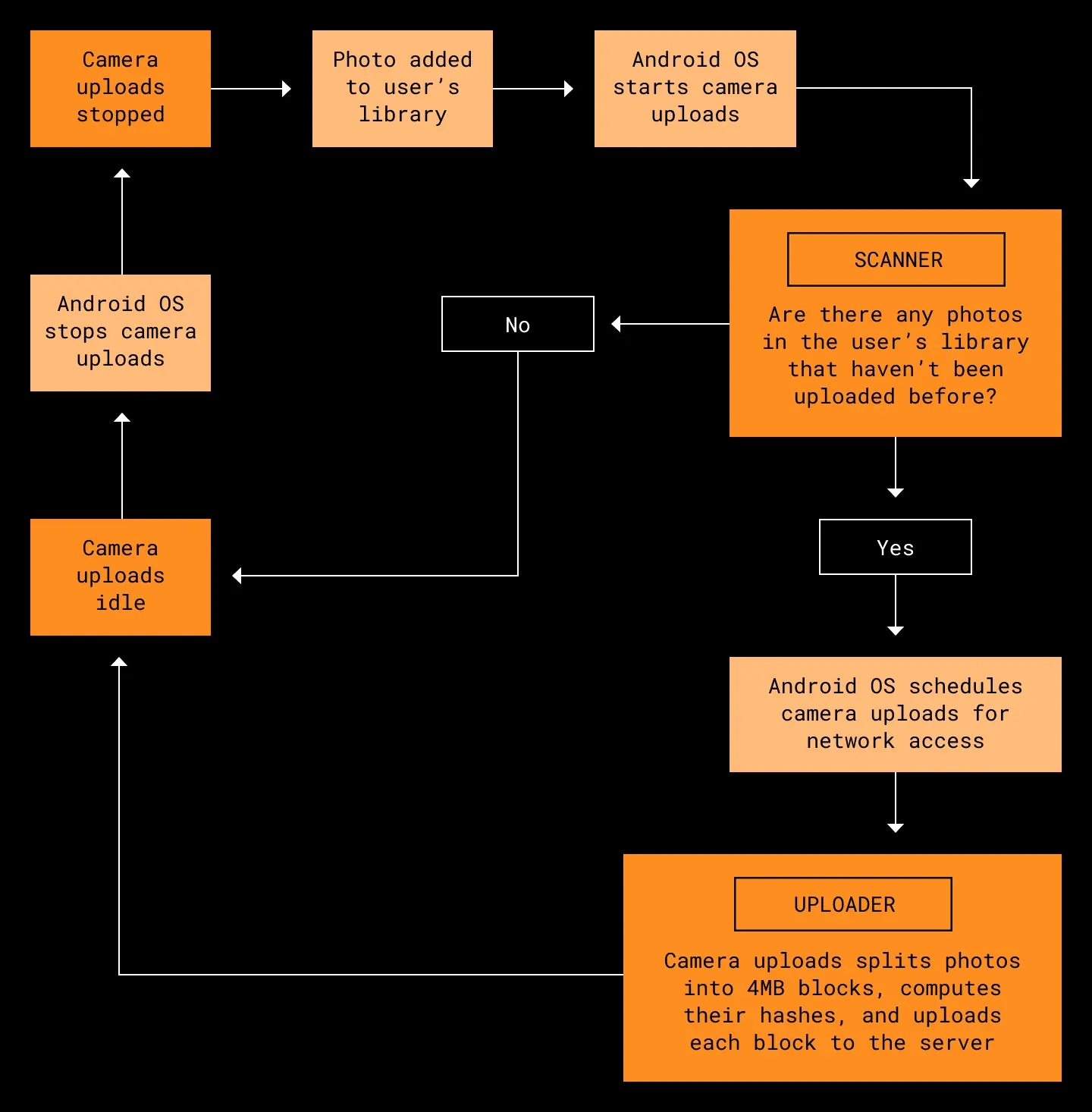
One of our biggest challenges is that Android places strong constraints on how often apps can run in the background and what capabilities they have. For example, App Standby limits our background network access if the Dropbox app hasn’t recently been foregrounded. This means we might only be allowed to access the network for a 10-minute interval once every 24 hours. These restrictions have grown more strict in recent versions of Android, and the cross-platform C++ version of camera uploads was not well-equipped to handle them. It would sometimes try to perform uploads that were doomed to fail because of a lack of network access, or fail to restart uploads during the system-provided window when network access became available.
Our rewrite does not escape these background restrictions; they still apply unless the user chooses to disable them in Android’s system settings. However, we reduce delays as much as possible by taking maximum advantage of the network access we do receive. We use WorkManager to handle these background constraints for us, guaranteeing that uploads are attempted if, and only if, network access becomes available. Unlike our C++ implementation, we also do as much work as possible while offline—for example, by performing rudimentary checks on new photos for duplicates—before asking WorkManager to schedule us for network access.
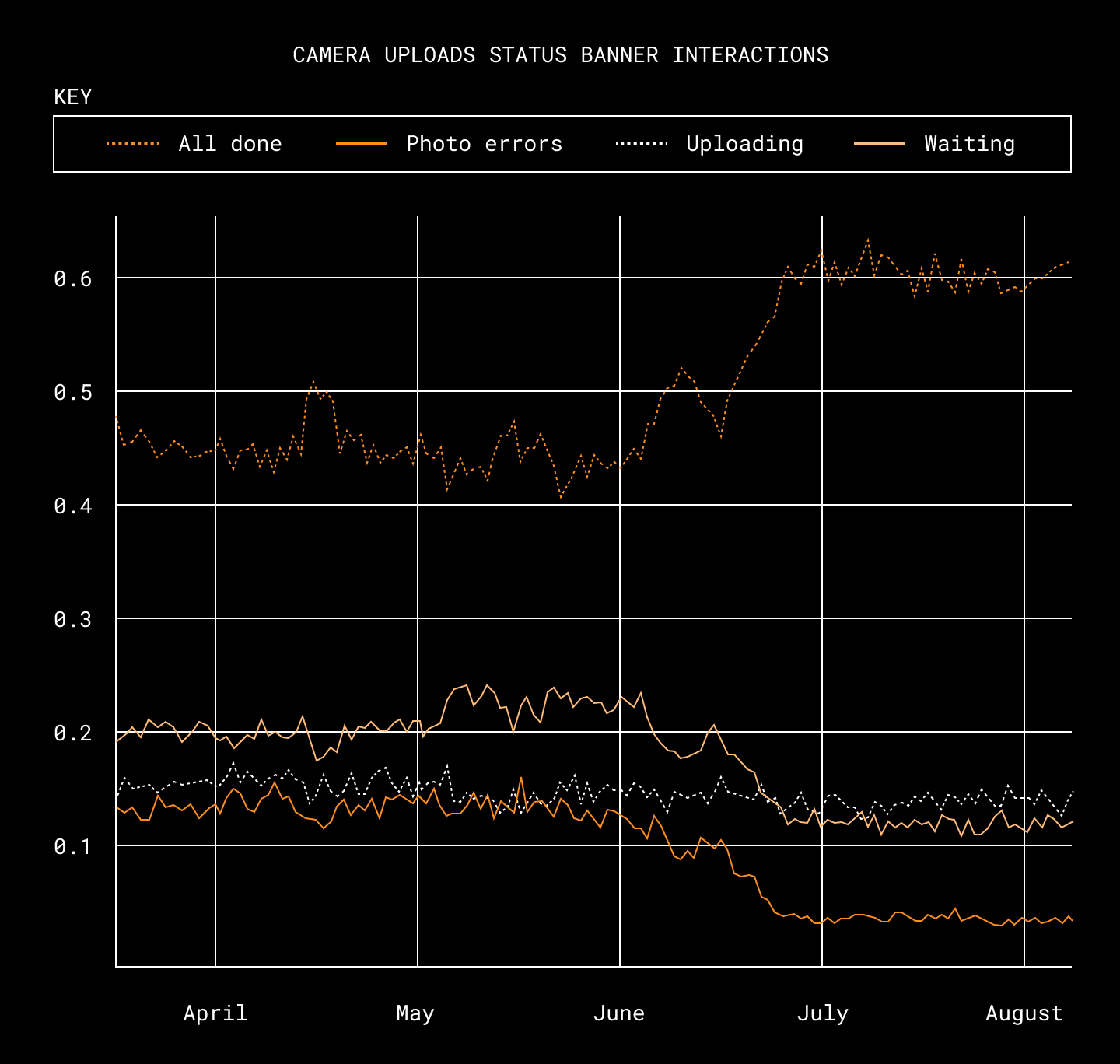
Measuring interactions with our status banners helps us identify emerging issues in our apps, and is a helpful signal in our efforts to eliminate errors. After the rewrite was released, we saw users interacting with more “all done” statuses than usual, while the number of “waiting” or error status interactions went down. (This data reflects only paid users, but non-paying users show similar results.)
To further optimize use of our limited network access, we also refined our handling of failed uploads. C++ camera uploads aggressively retried failed uploads an unlimited number of times. In the rewrite we added backoff intervals between retry attempts, and also tuned our retry behavior for different error categories. If an error is likely to be transient, we retry multiple times. If it’s likely to be permanent, we don’t bother retrying at all. As a result, we make fewer overall retry attempts—which limits network and battery usage—and users see fewer errors.
Designing for performance
Our users don’t just expect camera uploads to work reliably. They also expect their photos to upload quickly, and without wasting system resources. We were able to make some big improvements here. For instance, first-time uploads of large photo libraries now finish up to four times faster. There are a few ways our new implementation achieves this.
Parallel uploads
First, we substantially improved performance by adding support for parallel uploads. The C++ version uploaded only one file at a time. Early in the rewrite, we collaborated with our iOS and backend infrastructure colleagues to design an updated commit endpoint with support for parallel uploads.
Once the server constraint was gone, Kotlin coroutines made it easy to run uploads concurrently. Although Kotlin Flows are typically processed sequentially, the available operators are flexible enough to serve as building blocks for powerful custom operators that support concurrent processing. These operators can be chained declaratively to produce code that’s much simpler, and has less overhead, than the manual thread management that would’ve been necessary in C++.
val uploadResults = mediaUploadStore
.getPendingUploads()
.unorderedConcurrentMap(concurrentUploadCount) {
mediaUploader.upload(it)
}
.takeUntil {
it != UploadTaskResult.SUCCESS
}
.toList()A simple example of a concurrent upload pipeline. unorderedConcurrentMap is a custom operator that combines the built-in flatMapMerge and transform operators.
Optimizing memory use
After adding support for parallel uploads, we saw a big uptick in out-of-memory crashes from our early testers. A number of improvements were required to make parallel uploads stable enough for production.
First, we modified our uploader to dynamically vary the number of simultaneous uploads based on the amount of available system memory. This way, devices with lots of memory could enjoy the fastest possible uploads, while older devices would not be overwhelmed. However, we were still seeing much higher memory usage than we expected, so we used the memory profiler to take a closer look.
The first thing we noticed was that memory consumption wasn’t returning to its pre-upload baseline after all uploads were done. It turned out this was due to an unfortunate behavior of the Java NIO API. It created an in-memory cache on every thread where we read a file, and once created, the cache could never be destroyed. Since we read files with the threadpool-backed IO dispatcher, we typically ended up with many of these caches, one for each dispatcher thread we used. We resolved this by switching to direct byte buffers, which don’t allocate this cache.
The next thing we noticed were large spikes in memory usage when uploading, especially with larger files. During each upload, we read the file in blocks, copying each block into a ByteArray for further processing. We never created a new byte array until the previous one had gone out of scope, so we expected only one to be in-memory at a time. However, it turned out that when we allocated a large number of byte arrays in a short time, the garbage collector could not free them quickly enough, causing a transient memory spike. We resolved this issue by re-using the same buffer for all block reads.
Parallel scanning and uploading
In the C++ implementation of camera uploads, uploading could not start until we finished scanning a user’s photo library for changes. To avoid upload delays, each scan only looked at changes that were newer than what was seen in the previous scan.
This approach had downsides. There were some edge cases where photos with misleading timestamps could be skipped completely. If we ever missed photos due to a bug or OS change, shipping a fix wasn’t enough to recover; we also had to clear affected users’ saved scan timestamps to force a full re-scan. Plus, when camera uploads was first enabled, we still had to check everything before uploading anything. This wasn’t a great first impression for new users.
In the rewrite, we ensured correctness by re-scanning the whole library after every change. We also parallelized uploading and scanning, so new photos can start uploading while we’re still scanning older ones. This means that although re-scanning can take longer, the uploads themselves still start and finish promptly.
Validation
A rewrite of this magnitude is risky to ship. It has dangerous failure modes that might only show up at scale, such as corrupting one out of every million uploads. Plus, as with most rewrites, we could not avoid introducing new bugs because we did not understand—or even know about—every edge case handled by the old system. We were reminded of this at the start of the project when we tried to remove some ancient camera uploads code that we thought was dead, and instead ended up DDOSing Dropbox’s crash reporting service. 🙃
Hash validation in production
During early development, we validated many low-level components by running them in production alongside their C++ counterparts and then comparing the outputs. This let us confirm that the new components were working correctly before we started relying on their results.
One of those components was a Kotlin implementation of the hashing algorithms that we use to identify photos. Because these hashes are used for de-duplication, unexpected things could happen if the hashes change for even a tiny percentage of photos. For instance, we might re-upload old photos believing they are new. When we ran our Kotlin code alongside the C++ implementation, both implementations almost always returned matching hashes, but they differed about 0.005% of the time. Which implementation was wrong?
To answer this, we added some additional logging. In cases where Kotlin and C++ disagreed, we checked if the server subsequently rejected the upload because of a hash mismatch, and if so, what hash it was expecting. We saw that the server was expecting the Kotlin hashes, giving us high confidence the C++ hashes were wrong. This was great news, since it meant we had fixed a rare bug we didn’t even know we had.
Validating state transitions
Camera uploads uses a database to track each photo’s upload state. Typically, the scanner adds photos in state NEW and then moves them to PENDING (or DONE if they don’t need to be uploaded). The uploader tries to upload PENDING photos and then moves them to DONE or ERROR.
Since we parallelize so much work, it’s normal for multiple parts of the system to read and write this state database simultaneously. Individual reads and writes are guaranteed to happen sequentially, but we’re still vulnerable to subtle bugs where multiple workers try to change the state in redundant or contradictory ways. Since unit tests only cover single components in isolation, they won’t catch these bugs. Even an integration test might miss rare race conditions.
In the rewritten version of camera uploads, we guard against this by validating every state update against a set of allowed state transitions. For instance, we stipulate that a photo can never move from ERROR to DONE without passing back through PENDING. Unexpected state transitions could indicate a serious bug, so if we see one, we stop uploading and report an exception.
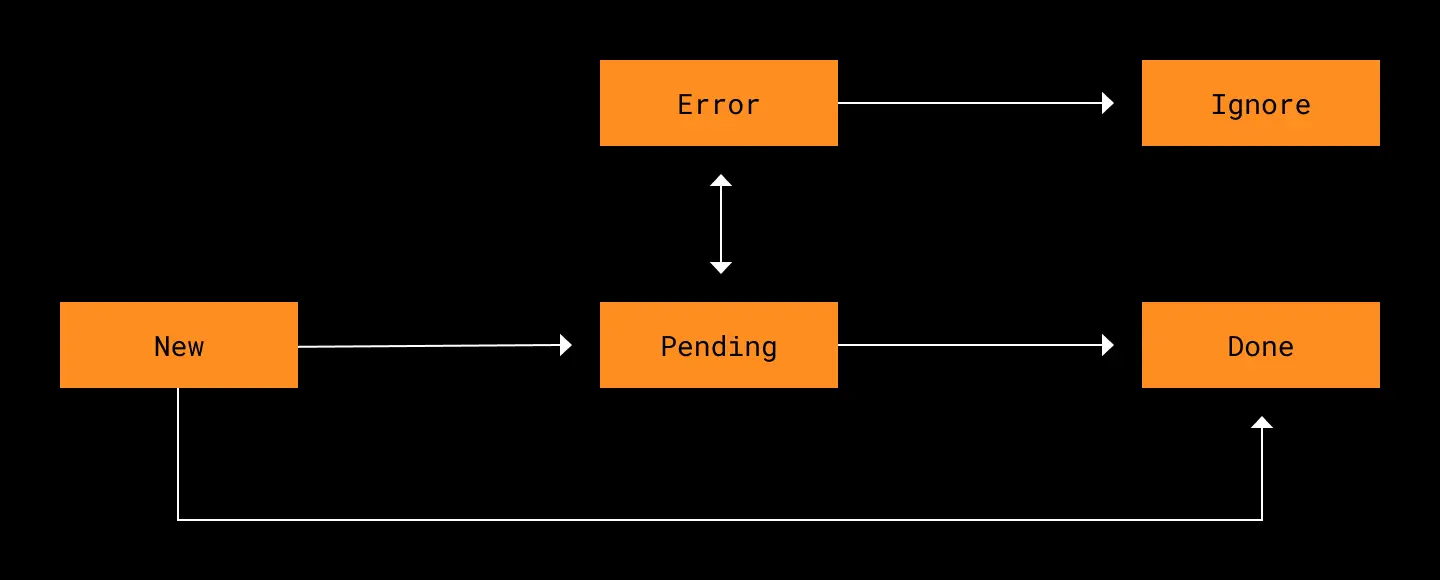
These checks helped us detect a nasty bug early in our rollout. We started to see a high volume of exceptions in our logs that were caused when camera uploads tried to transition photos from DONE to DONE. This made us realize we were uploading some photos multiple times! The root cause was a surprising behavior in WorkManager where unique workers can restart before the previous instance is fully cancelled. No duplicate files were being created because the server rejects them, but the redundant uploads were wasting bandwidth and time. Once we fixed the issue, upload throughput dramatically improved.
Rolling it out
Even after all this validation, we still had to be cautious during the rollout. The fully-integrated system was more complex than its parts, and we’d also need to contend with a long tail of rare device types that are not represented in our internal user testing pool. We also needed to continue to meet or surpass the high expectations of all our users who rely on camera uploads.
To reduce this risk preemptively, we made sure to support rollbacks from the new version to the C++ version. For instance, we ensured that all user preference changes made in the new version would apply to the old version as well. In the end we never ended up needing to roll back, but it was still worth the effort to have the option available in case of disaster.
We started our rollout with an opt-in pool of beta (Play Store early access) users who receive a new version of the Dropbox Android app every week. This pool of users was large enough to surface rare errors and collect key performance metrics such as upload success rate. We monitored these key metrics in this population for a number of months to gain confidence it was ready to ship widely. We discovered many problems during this time period, but the fast beta release cadence allowed us to iterate and fix them quickly.
We also monitored many metrics that could hint at future problems. To make sure our uploader wasn’t falling behind over time, we watched for signs of ever-growing backlogs of photos waiting to upload. We tracked retry success rates by error type, and used this to fine-tune our retry algorithm. Last but not least, we also paid close attention to feedback and support tickets we received from users, which helped surface bugs that our metrics had missed.
When we finally released the new version of camera uploads to all users, it was clear our months spent in beta had paid off. Our metrics held steady through the rollout and we had no major surprises, with improved reliability and low error rates right out of the gate. In fact, we ended up finishing the rollout ahead of schedule. Since we’d front-loaded so much quality improvement work into the beta period (with its weekly releases), we didn’t have any multi-week delays waiting for critical bug fixes to roll out in the stable releases.
So, was it worth it?
Rewriting a big legacy feature isn’t always the right decision. Rewrites are extremely time-consuming—the Android version alone took two people working for two full years—and can easily cause major regressions or outages. In order to be worthwhile, a rewrite needs to deliver tangible value by improving the user experience, saving engineering time and effort in the long term, or both.
What advice do we have for others who are beginning a project like this?
- Define your goals and how you will measure them. At the start, this is important to make sure that the benefits will justify the effort. At the end, it will help you determine whether you got the results you wanted. Some goals (for example, future resilience against OS changes) may not be quantifiable—and that’s OK—but it’s good to spell out which ones are and aren’t.
- De-risk it. Identify the components (or system-wide interactions) that would cause the biggest problems if they failed, and guard against those failures from the very start. Build critical components first, and try to test them in production without waiting for the whole system to be finished. It’s also worth doing extra work up-front in order to be able to roll back if something goes wrong.
- Don’t rush. Shipping a rewrite is arguably riskier than shipping a new feature, since your audience is already relying on things to work as expected. Start by releasing to an audience that’s just large enough to give you the data you need to evaluate success. Then, watch and wait (and fix stuff) until your data give you confidence to continue. Dealing with problems when the user-base is small is much faster and less stressful in the long run.
- Limit your scope. When doing a rewrite, it’s tempting to tackle new feature requests, UI cleanup, and other backlog work at the same time. Consider whether this will actually be faster or easier than shipping the rewrite first and fast-following with the rest. During this rewrite we addressed issues linked to the core architecture (such as crashes intrinsic to the underlying data model) and deferred all other improvements. If you change the feature too much, not only does it take longer to implement, but it’s also harder to notice regressions or roll back.
In this case, we feel good about the decision to rewrite. We were able to improve reliability right away, and more importantly, we set ourselves up to stay reliable in the future. As the iOS and Android operating systems continue to evolve in separate directions, it was only a matter of time before the C++ library broke badly enough to require fundamental systemic changes. Now that the rewrite is complete, we’re able to build and iterate on camera uploads much faster—and offer a better experience for our users, too.
Also: We're hiring!
Are you a mobile engineer who wants to make software that’s reliable and maintainable for the long haul? If so, we’d love to have you at Dropbox! Visit our jobs page to see current openings.


