

When Magic Pocket adopted SMR drives in 2017, one of the design decisions was to use SSDs as a write-back cache for live writes. The main motivation was that SMR disks have a reputation for being slower for random writes than their PMR counterparts. To compensate, live writes to Magic Pocket were committed to SSDs first and acknowledgements were sent to upstream services immediately. An asynchronous background process would then flush a set of these random writes to SMR disks as sequential writes. Using this approach, Magic Pocket was able to support higher disk densities while maintaining our durability and availability guarantees.
The design worked well for us over the years. Our newer generation storage platforms were able to support disks with greater density (14-20 TB per disk). A single storage host—with more than 100 such data disks and a single SSD—was able to support 1.5-2 PBs of raw data. But as data density increased, we started to hit limits with maximum write throughput per host. This was primarily because all live writes would pass through a single SSD.
We found each host's write throughput was limited by the max write throughput of its SSD. Even the adoption of NVMe-based SSD drives wasn't enough to keep up with Magic Pocket’s scale. While a typical NVMe based SSD can handle up to 15-20 Gbps in write throughput, this was still far lower than the cumulative disk throughput of hundreds of disks on a single one of our hosts.
This bottleneck only became more apparent as the density of our storage hosts increased. While higher density storage hosts meant we needed fewer servers, our throughput remained unchanged—meaning our SSDs had to handle even more writes than before to keep up with Magic Pocket’s needs.
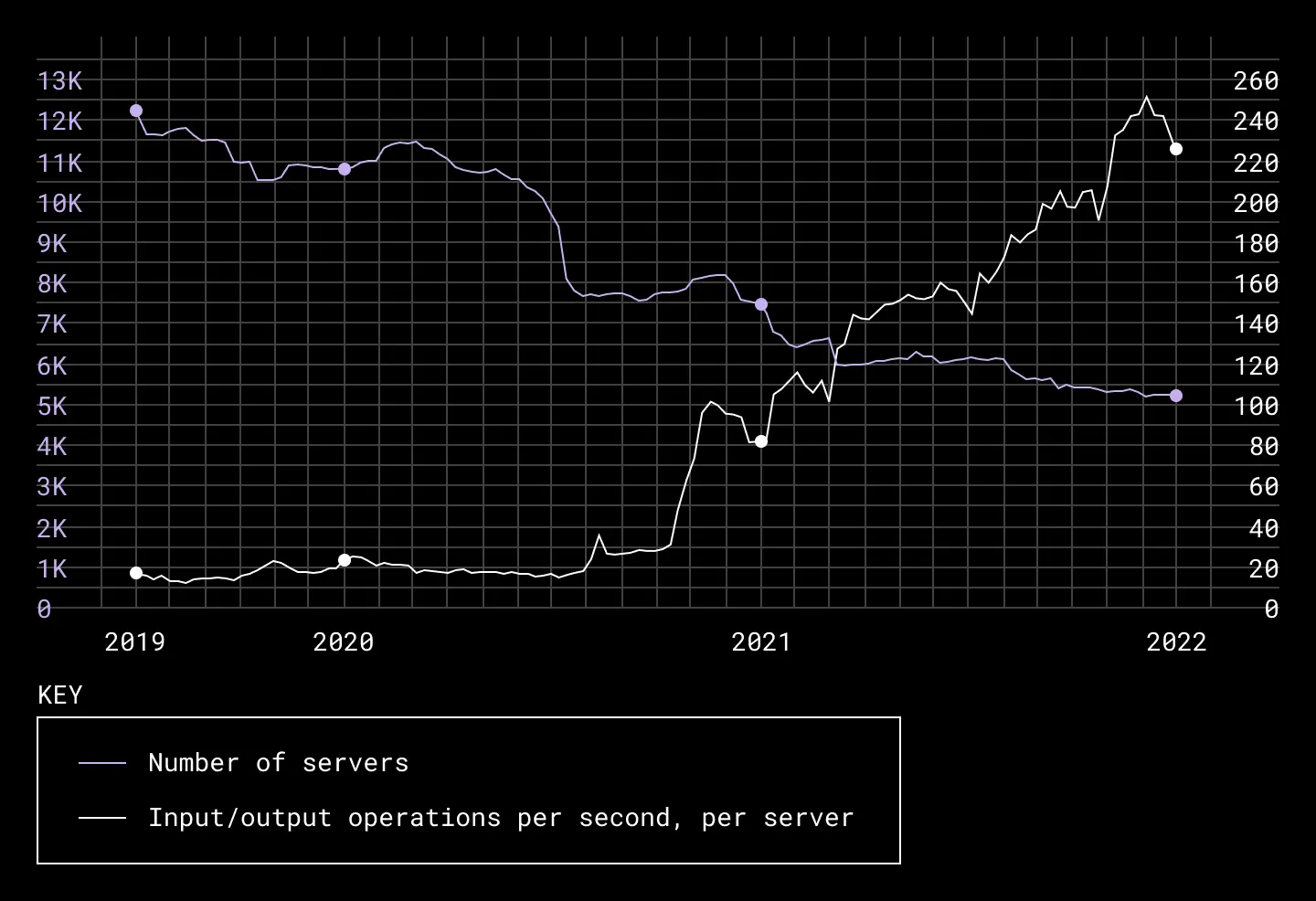
As the number of servers went down, throughput per server went up as a result
In 2021, we decided to address this bottleneck by bypassing our SSD cache disks for live writes entirely. We re-imagined Magic Pocket’s storage architecture to write directly to SMR disks while maintaining the same durability, availability and latency guarantees. As a result, we were not only able to increase write throughput by 15-20%, but also improve the reliability of our storage infrastructure and reduce our overall storage costs.
Why we did it
Throughput wasn’t the only problem we were grappling with. In early 2020, Magic Pocket experienced an incident where a large number of SSD disks failed within a short period. These SSDs were added to our fleet roughly around the same time and followed similar write patterns through their lifetime. As a result, many of these SSDs reached their maximum write endurance around the same time, too.
This caused Magic Pocket to perform a massive number of data repairs at once, posing a significant risk to durability. Magic Pocket did eventually repair all the data and there was no actual durability impact. But the incident forced us to think hard about how we could mitigate the risk of SSD failures going forward.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
There was also the operational overhead that came with sourcing and maintaining SSDs in our fleet. For every new generation of our server hardware, SSDs had to be qualified for reliability, durability and efficiency by our hardware engineers. Capacity and supply chain teams were also required to maintain operational and sourcing projections for future SSD demands.
Removing SSDs would not only help the Magic Pocket team overcome a worsening bottleneck. It would also eliminate a single point of failure, reduce infrastructure complexity for our hardware and data center operations teams, and save us time and money sourcing and maintaining SSDs in our fleet. Given the potential advantages, we decided to explore the possibility of removing SSDs from Magic Pocket during Hack Week in 2021.
Updating our storage engine
Magic Pocket organizes blocks into extents—containers of blocks—typically 1-2 GB in size. When an extent is open, it is able to accept writes; new blocks can be appended until the extent reaches its maximum size. Once full, the extent is closed, making it immutable and read-only.
These extents were already ideal for SMR disk sequential-only workloads. Because Magic Pocket's storage engine was setup to guarantee sequential writes and map extents onto a fixed set of SMR zones, we didn’t have to change much to support SMR-style sequential writes.
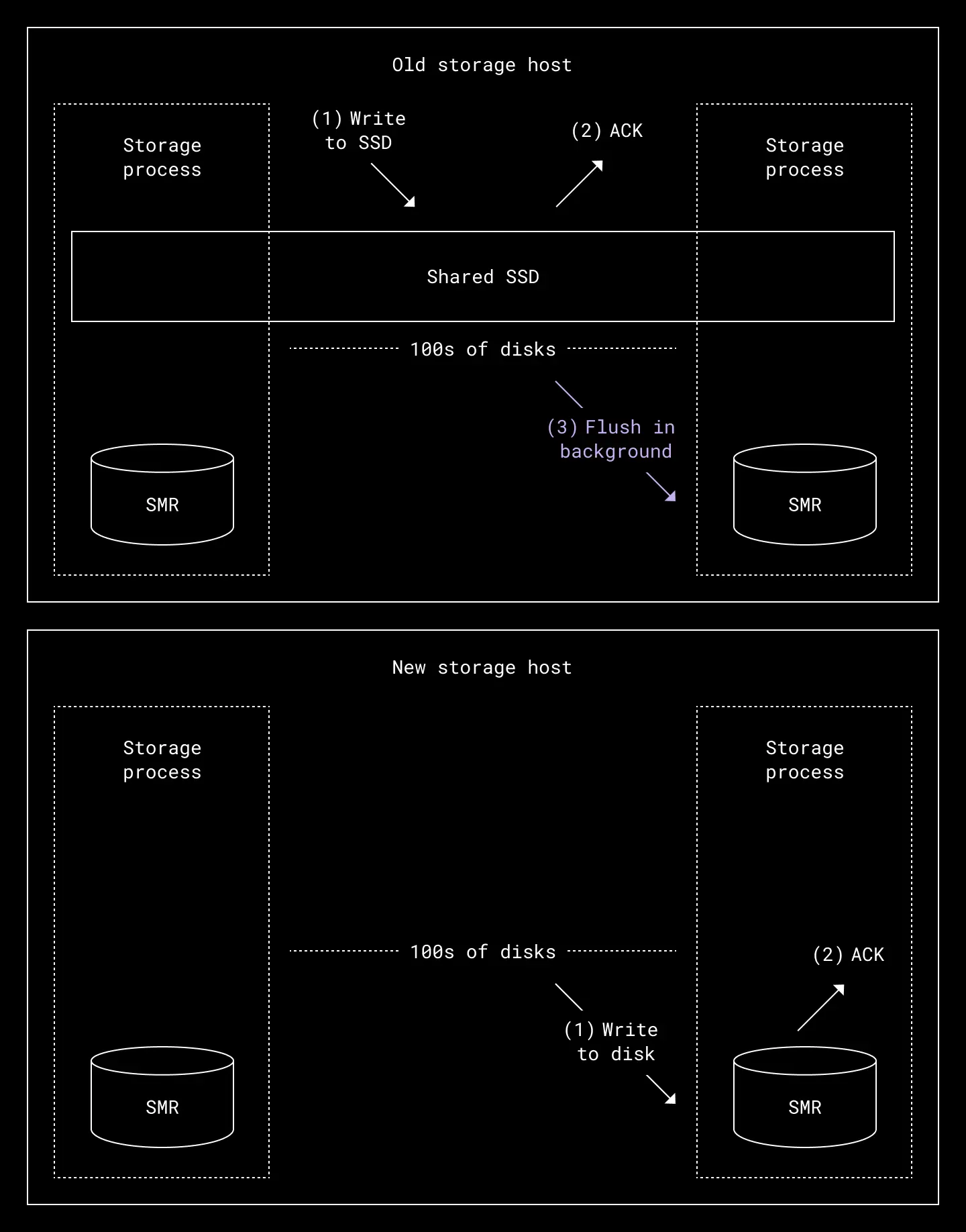
The architecture of our storage engine before and after we removed SSDs
Our storage engine’s existing implementation of open extents stored block metadata—such as block length and hashes—on SSD cache disks, while raw block data was stored on SMR disks. To get rid of the SSD cache, we would have to store both block metadata and raw block data on the same SMR disk.
We introduced a new extent format which stored block metadata and raw block data inline. On startup, the storage engine would parse the data on extents into metadata and raw data. It would then build an in-memory index mapping each block to its offset in the extent. On each new block write, blocks were inlined with their metadata, serialized, and committed to the SMR disk directly.
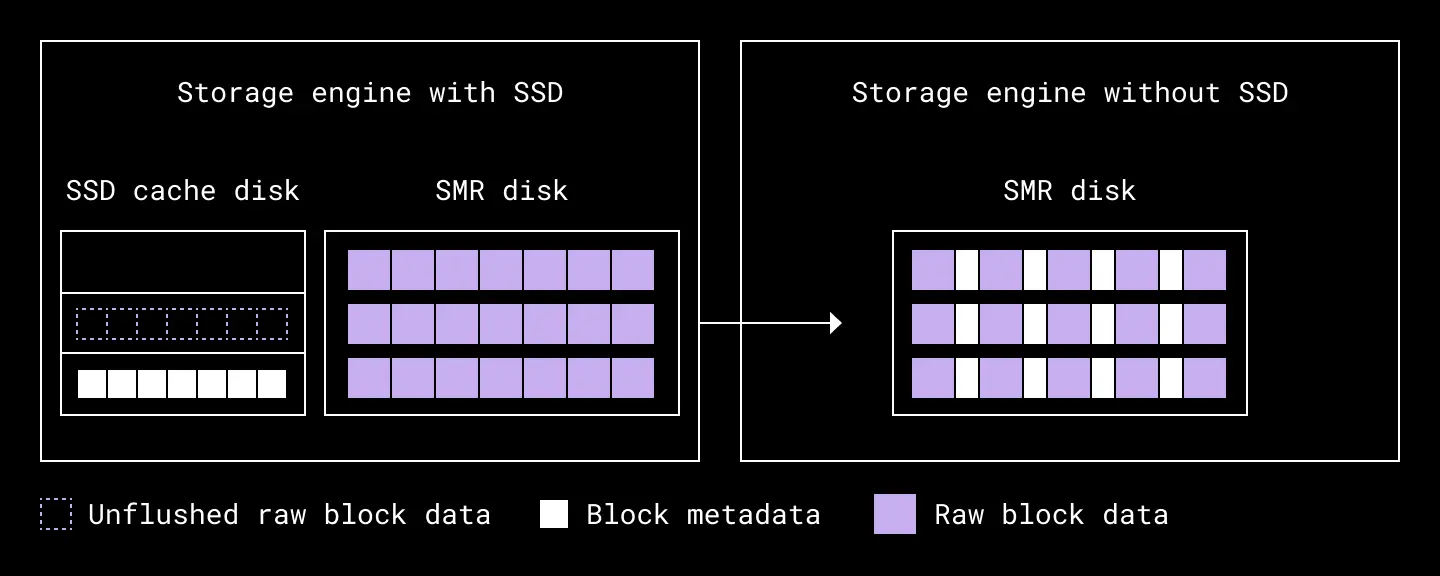
Our open extent format before and after removing SSDs from Magic Pocket
We also made changes to the control plane workflows around disk repair, disk allocation and deallocation. When a new host was provisioned, the SSD cache was formatted, partitioned, and assigned to SMR disks. There were also workflows that automatically detected SSD failures and flagged them for repair. Writing directly to SMR disks meant these operations were no longer needed.
Testing and tradeoffs
As we made changes to the storage engine, it was important we had confidence in its ability to recover from sudden crashes, partial writes, and bit rot. We wrote an automated tool to simulate such conditions and verify if the storage engine’s startup succeeded in all such failure scenarios. We also tested the new extent format on background traffic first.
Our load tests yielded very encouraging results. When the system was configured to run under peak throughput, we saw write throughput increase by 2-2.5x. p95 latencies for write operations improved by 15-20% as well.
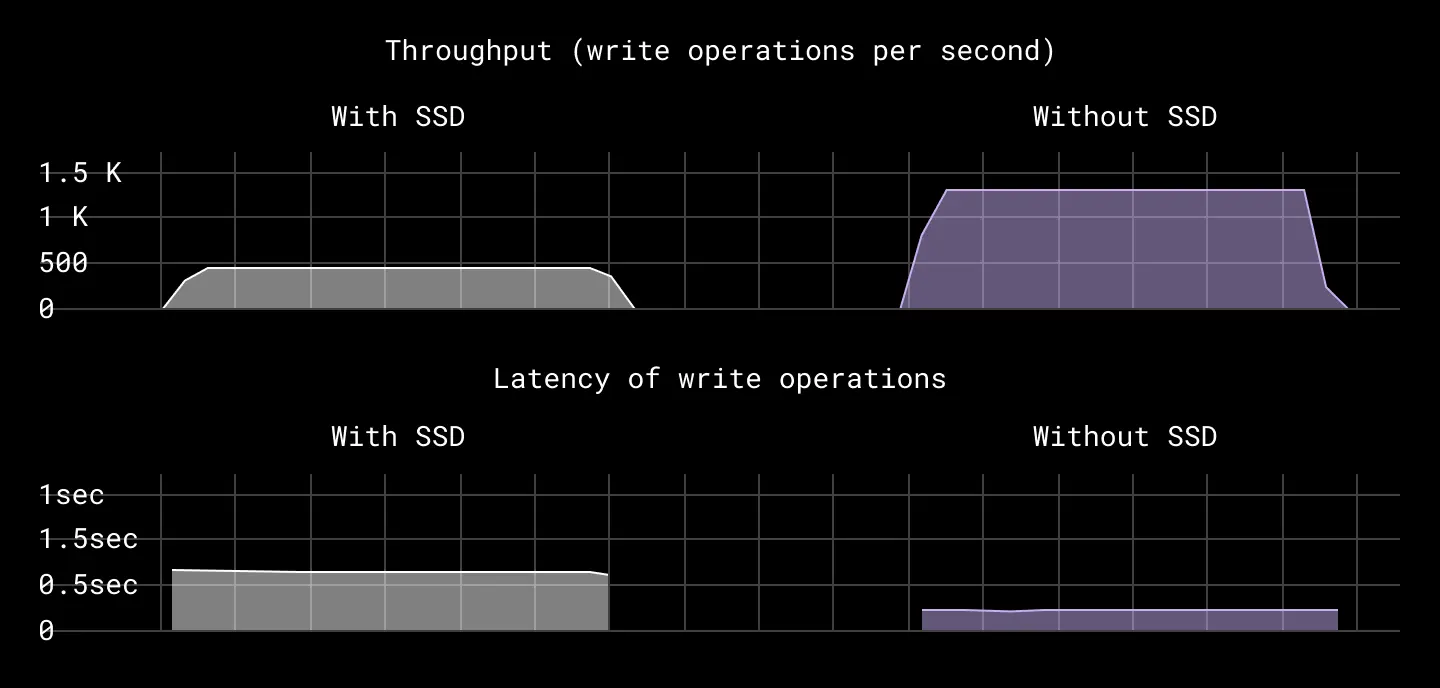
Throughput and p99 latencies of operations with and without SSDs
In production, however, we operate much below peak throughput capacity—we try to average out load across all available hosts and disks—so we knew we would not see the same results. In fact, under average load scenarios, the p95 of last mile disk write latencies actually increased by 10-15%. This is because writing to an SMR disk is obviously slower than writing to an SSD. However, this is only a 2% increase in Magic Pocket’s overall end-to-end write latency (which includes front end, metadata storage, and storage engine latencies). We were willing to accept this tradeoff in exchange for the advantages gained.
The other tradeoff was an increase in latency for certain read operations. Our storage engine used to maintain an in-memory cache for all recently written blocks. This was done to account for cases where a block may not have yet been flushed from the SSD to the SMR disk. In such cases, we could read these blocks from this in-memory cache instead of reading them from SSDs. With the removal of SSDs, we had to get rid of this read block cache. This did impact the latency of our reads, especially for recently written blocks. However, we didn’t see a significant impact on our p99 latencies. If we did see an impact in the future, we reasoned we could always add a block cache layer back to our storage engine.
The rollout
With the success of our Hack Week project we decided to prepare the feature for production. We started with a subset of Magic Pocket hosts. The more confidence we gained, the more hosts we included. By end of Q1 2022, all SSDs had been successfully removed from Magic Pocket and our storage hosts were writing directly to SMR drives.
Now that we are no longer limited by the throughput of our SSDs, overall write throughput across our storage fleet has increased by 15-20%. This has and helped us meet the ever increasing throughput requirements of new Magic Pocket workloads, while keeping our storage fleet the same size.
There have been other benefits, too. On average, 8-10 SSD disks would fail each month, requiring the Data Center Operations team to manually inspect, repair, and/or replace each drive. Removing our SSD cache disks eliminates a single point of failure and has also reduced our repair rate. And with one less component to design around, removing SSDs has also reduced the complexity of hardware platform design for our Hardware team.
The project has been a big win for reliability, efficiency, and cost at Dropbox. If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.
Special thanks to Ankur Kulshrestha, Rajat Goel, Sandeep Ummadi, Facundo Agriel, Bill Fraser, Derek Lokker, Toby Burress, Akshet Pandey, Ross Guarino, Elijah Mirecki, Josh Wolfe, Jared Mednick, Jason Holpuch and Eric Shobe.


